from mcedit to vim
Tl;DR
It’s a blog post about text editor. You probably want to ignore it :)
I tried vim again and got it to behave close enough to mcedit. Now I
can use it with the following minimal .vimrc:
silent! source $VIMRUNTIME/defaults.vim
colorscheme darkblue
" default color is invisible blue-on-blue
highlight MatchParen ctermbg=green
" just maintain the indent
set autoindent
" copy the indentation style from previous line
set copyindent
" do preserve tab/space mix on change
set preserveindent
" always render tabs even if a single file is open
set showtabline=2
" always render status line below
set laststatus=2
set list
set listchars=tab:<->,trail:.
" vim enables xterm-style Ctrl-<arrows> keys based on $TERM variable
" name. term=screen-256color does not trigger it. Let's work it around
" by clobbering it.
set term=xterm-256colorAnd it looks like that:
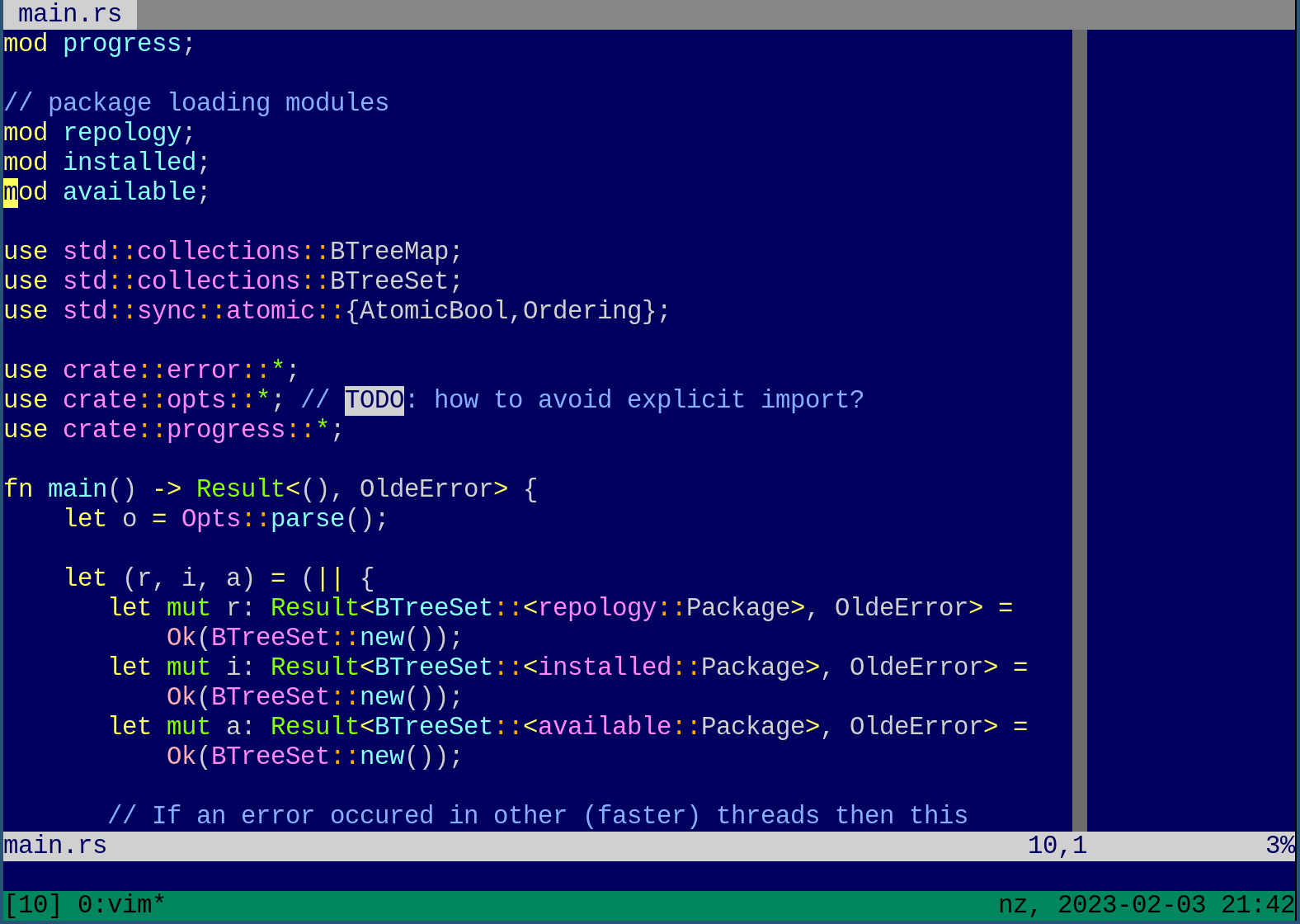
If you really want to know my path to vim here is a long story.
MS-DOS times
My first ever encounter with text editors was a monochrome blue/white LCD display. It was attached to some 286 “portable” computer weighting about 20 kilograms. It emitted the calming buzzing sound I will never forget. And it ran Norton Commander as the primary shell.
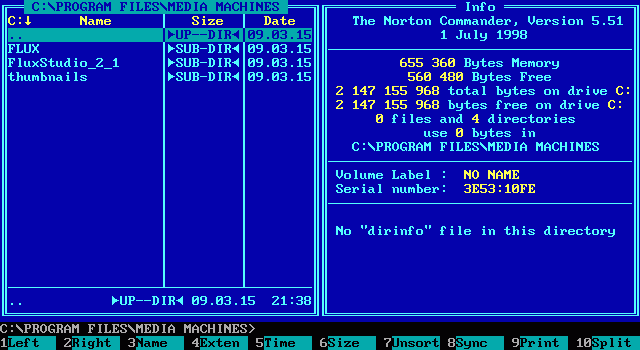
Others also used Volkov Commander clone. It looks almost identical to the untrained eye.
They both had an editor built right into file manager accessible via
<F4> key binding. I did not edit many files there and only saw others
doing it.
Windows times
On windows machines I used Total Commander
as a shell and don’t remember much about the editors I used. Bare
notepad was probably a thing. Windows environment did not have many
text files to tweak. Thus, it was not important.
The tiny amount of programming I did happened in
Turbo Pascal IDE and in
Visual Studio 6.0.
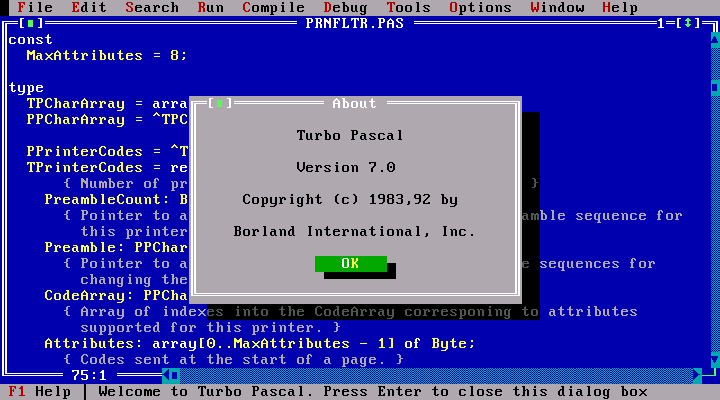
Turbo Pascal was a great IDE: it had syntax highlighting, go-to-error
navigation, built in compile/build progress reporter, breakpoint
debugger, intuitive compiler flag combo boxes and may other things I did
not appreciate at the time. Being a DOS-based program it looked like a
miracle.
It defined my expectation of the ideal environment.
Linux times
In the first year of university I started writing first non-trivial
programs. Around the same time I switched to Linux as my desktop.
Linux (as you might already suspect at this point) was full of text
files one has to tweak to adapt it to your environment. It was even more
important in those day than nowadays. One of the books I bought (of
“Linux for dummies” kind) allocated about 200 pages on the problem of
getting Russian language (or at least character set) and fonts to work in
various programs. Text editors, audio players, gtk apps, qt apps,
x11 apps, email programs, file system encodings all had to be
re-configured (and sometimes patched) for interoperability
with dual-booted windows.
To give you a gist of the kind of the problems one encountered: Russian
had 3 popular 8-bit character sets at the time. CP866 was used in MS-DOS.
CP1251 aew used in windows GUI. And KOI8-R was used in e-mail and many
Linux distributions (but not all of them!). There was also an
ISO-8859-5 I never saw being used in real world.
Russian encodings digression
All Russian encoding have their own strange and charming properties.
KOI8-R is the
fanciest of the three: it’s main design is to remain readable even if
highest bit of each byte is stripped by unforgiving email or terminal
systems out there that assumed 7-bit ASCII.
So the Cyrillic text would be mangled into a transliterated version of Russian:
$ echo 'Ужасы кодировок времен царя Гороха' | iconv -t koi8-r | perl -pe 'tr/\x80-\xFF/\x00-\x7F/' | iconv -f koi8-r
uVASY KODIROWOK WREMEN CARQ gOROHA
$ echo 'АБВГДЕЁЖЗИЙКЛМПОНРСТУФХЦЧШЩЪЫЬЭЮЯ' | iconv -t koi8-r | perl -pe 'tr/\x80-\xFF/\x00-\x7F/' | iconv -f koi8-r
abwgde3vzijklmponrstufhc~{}yx|`q
$ echo 'абвгдеёжзийклмнопрстyфxцчшщъыьэюя' | iconv -t koi8-r | perl -pe 'tr/\x80-\xFF/\x00-\x7F/' | iconv -f koi8-r
ABWGDE#VZIJKLMNOPRSTyFxC^[]_YX\@QSome of the letters are missing: it’s not very easy to map 33 Cyrillic letters into 26 Latin ones. You have only one bit to flip and do translation consistently across upper and lower case. It’s a marvelous hack.
To clarify: even being a native language speaker it’s not easy to read such mangled text. But at least you can recognize most words and guess strange letters. If you know nothing about Cyrillic you can spot the similarities (and differences) in Cyrillic and Latin alphabets side by side.
This way of construction means that Cyrillic letters don’t go in
alphabetic order in KOI8-R character set. They are scattered all over the
space. This means that naive sorting based on strcmp() does not
produce anything close to alphabetic sorting.
CP866 and
CP1251 are mostly safe in
this regard. But they also have their own caveats.
For example in CP1251 я letter has 0xFF value. Many programs at
that time had a bug of this sort:
FILE * f = ...;
char c;
while ((c = getc(f)) != EOF) {
...
}The bug here is in getc() result (of type int) truncation down to
c (of type char).
In != comparison signed char systems sign-extend 0xFF ((char)-1)
to 0xFFffFFff ((int)-1, and EOF).
As a result some text editors (or even FTP and IRC clients and
servers!) unaware of Cyrillic would silently eat rest of your file if
you were to type (or receive!) ‘я’ in it.
While strcmp() produces mostly alphabetical sorting there is one
exception: it’s the letter Ё / ё. It stands outside the rest of
the alphabet probably because it’s not present in all Slavic Cyrillic
alphabets.
It took the ecosystem quite a while to adopt strcoll() style sorting.
And then UTF-8 came and broke it again.
Back to Linux: towards mc
Given the proliferation of encoding one’s text editor should better
support all these encodings. Alas, I picked one that does not. I stuck
to something that resembles my good old Norton Commander friend:
Midnight Commander

There I felt at home. Most of the key bindings were still the same, functional keys were nicely documented right on the screen. And built-in editor had a bit of syntax highlighting! What else do you need?!
My system had LANG=ru_RU.KOI8-R locale at the time. It did not have
any troubles with text files in English. Some functional keys on the
other hand were off-by-two in urxvt. But they were working fine on
xterm. So I used xterm.
mcedit did not support file encoding different from LC_CTYPE at the
time. In rare moments of dire need I used things like
luit as a cheap hack to get
something edited. I could not get iconv tool to work right. Fun times.
First attempt as vim
At some point I decided to build
LFS as a way to
learn Linux internals.
When I built it for the first time I needed an editor at an early stage
of system preparation. I ended up trying vim. Maybe it was a default?
I don’t remember.
I copied .vimrc from my previous distribution (Alt Master 2.2, a
Mandrake sibling). Here is it’s full content:
" Begin .vimrc
set nocompatible
set bs=2
" set columns=80
set background=dark
set wrapmargin=8
syntax on
set ruler
set encoding=utf-8
set fenc=utf-8
set fencs=utf-8,koi8-r
set cindent
set shiftwidth=4
" End .vimrcI had no idea what exactly the above config did. In hindsight it’s worst
bit was the set wrapmargin=8 option. In case you are not familiar with
that vim option: it inserts newlines in strings automatically as soon
as you get as close as 8 characters to the visible boundary of the
screen from the right. As in, it inserts newlines in different places
depending on size of your terminal. And I was not used to vim enough
to spot that it does this thing. I had to open files in mcedit later
to find the effect.
In my case the first casualty was /etc/fstab: it wrapped half the
mount options to the newline and I got an unbootable system. When I
figured that it was vim deed I decided it was too dangerous to use
as it silently corrupts files.
On top of that I did not like black vim background: it felt void.
Plus multiple editing modes confused me. I did not understand why you
have to print <ESC>:qa! and sometimes just :qa!. I did not do a
vimtutor as I did not know it existed: I did not pay much attention to
various help banners vim pops at you at start.
Being a default editor in the distribution it felt like a handicap archaic tool. I though it was not supposed to be a complete editor with a long list of features. Ironically I thought it’s something primitive because it started up so quickly.
First attempt at emacs
A bit later I got a day job related to C++. I started exploring
IDE-like environments. I can only remember Anjuta and Eclipse. There
were a lot more I tried. They all were too slow and opinionated, needed
project files, did not understand autotools-based projects. I quickly
rejected them all.
Around that time I got daily internet access where I found all sorts of
things about how cool Lisp and Emacs are. I started using Emacs
for most of file editing and read a few books on Common Lisp. I did
not write anything sizable in Lisp. Best I could do is to draw an
OpenGL rectangle using verrazano FFI library for sbcl.
In C++ land I tried ECB, CEDET and Bovinator for parsing and
autocompletion. The result looked suboptimal (manly because our build
system injected too many defines external parsers did not know about).
The plugins slowed emacs loading a lot. To save on startup time I
tried to use emacsclient. I was using X11 version of Emacs.
Switching workspace to edit a file was very inconvenient.
I disabled heavyweight extension and used Emacs itself for a while.
Writing this blog post I found that emacsclient -nw works just as
expected. It seems to do what I needed back then: it starts up quickly
as a client. Maybe I’ll give Emacs another try as well. I’m so used to
it’s key bindings in editor mode.
Back to mcedit
Disappointed in slow Emacs start up times I settled on mcedit and
used it for most of my editing since. It looked perfect: so close to
nc.exe, trivial to extend syntax highlighting files with new keywords.
Apparently I even contributed
haskell.syntax
and ebuild.syntax.
At that time a new mc development team was formed by Russian-speaking
community of mc users to revive stalled upstream development. I joined
and contributed a tiny bit to mc. I like to think I helped with
subversion to git migration, fixed a few dire corner cases in
completion code, fixed a few bugs in FISH file transfer protocol,
basic alacritty support and even support for compilation with
tinycc.
All the above helped me track and use new features in development in
mcedit: vertical block selection (Alt-<arrows>), tab/space
highlighting (Alt-_), file encoding selection (Ctrl-e), tag
completion (ESC-Tab) and many other things I take for granted today.
mc was my IDE for many years and mcedit helped editing all the text
files for me. Be it blog posts like this one, Makefiles, C projects,
Haskell projects, /etc/fstab entries. I even successfully patched
binary files with it.
Various snags
There are many gnarly bits in mc and mcedit. Most of them stem from
the complex problem space. To name a few:
mcis full ofterminfooverrides (which are sometimes invalid and outdated) because distributions’terminfodatabases are too old. Files likemisc/mc.libought to be empty in a perfect system.mchas to interface with underlying shell (that you can access overCtrl-O) by sending shell text commands likecd $dirwhen you move around directories and run executables. Path escaping and process progress is shell-dependent. State tracking is easy to confuse by running a subshell.mcedithas it’s own (inefficient) syntax highlighter with it’s own syntax file format. This means most language syntaxes have to be reimplemented on it. It’s not too bad for simple languages. But very fragile for languages that allow you to embed another language in it’s snippets: markdown with code snippets, shell with$(subshell calls "strings $(more subshell)").mceditwhile being a large part ofmcis not the primary feature of it.mcis primarily a file manager that happens to have an editor.mceditdoes not have that many contributors and lacks an easy way to extend it. Things liketagscompletion oraspellsupport are implemented directly inCcode. There is no easy way to hack up a simple equivalent.
These are not major issues to get something basic to work. My use of
mc for past 20 years is a good indication of that.
Recently I went through the problems of AoC 2015
just to practice in rust a bit more. I encountered a simple json
parsing problem (2015/12). It’s
input
is a single line of json text. The line was 37K long. Tiny by today’s
standards.
I selected the line in the browser and pressed Shift+Insert in
mcedit window to paste it.
Guess how long it took to insert the text into an otherwise empty
freshly opened file. 1 second? 10 seconds? 1 year? What would you
expect from your editor?
Got the guesstimate?
It took 40 seconds. What is worse: while pasting is in progress UI shows
you interactively the speed of text insertion (good). First 10K got
inserted within 2-3 second, next 10K took about 10 more seconds maybe,
and next 10K takes 25. This is quadratic behavior right there (bad).
I thought it’s a minor bug. I knew mc does somewhat complex
arithmetic on multi-byte strings when moves around characters in them.
But it’s not supposed to get that much worse.
I filed a bug with the
perf dump below to quickly highlight problematic bit:
26,69% mc [.] edit_buffer_get_utf
25,02% mc [.] edit_move_forward3
14,99% mc [.] edit_buffer_get_byte
9,16% libglib-2.0.so.0.7400.3 [.] g_utf8_get_char_validated
5,51% libglib-2.0.so.0.7400.3 [.] g_unichar_iswide
4,33% mc [.] edit_buffer_get_bol
1,88% mc [.] g_utf8_get_char_validated@pltAnd got a response that such behaviour is not specific to mcedit and
should plague other editors as well. I though it sounded a bit wrong.
My expectation was that paste speed should be linear to pasted input,
not quadratic.
I tried to find at least one editor that would behave poorly for this
specific use case and found none. Anything I tried was able to do it in
1-2 seconds: vim, emacs -nw, nano, gedit, geany, kwrite,
helix, some Java-based editors I forgot. They all were reasonably
fast.
Unrelated to the above roughly around that time I planned to share one
of my blog posts to wider audience. I knew my text is always full of
typos and I wanted an easy interactive tool to highlight trivial typos
I did. I ran a few tools on my post and they all highlighted typos in
slightly different places: some looked at the code comment, some didn’t,
some used external aspell engine, some used embedded grammar engines.
I settled on vim’s :setlocal spell! magic spell.
vim again
Having got a bit of positive experience with spell checking I decided to
give vim another try. I did not want to write any complex
configuration as I have many editing environments and would prefer to be
able to get an editor into a comfortable state with a few commands or a
few lines in the config.
I went through my initial ~/.vimrc from the ancient times to see if I
still needed any of that:
" Begin .vimrc
set nocompatible
set bs=2
" set columns=80
set background=dark
set wrapmargin=8
syntax on
set ruler
set encoding=utf-8
set fenc=utf-8
set fencs=utf-8,koi8-r
set cindent
set shiftwidth=4
" End .vimrcI found that pesky wrapmargin=8 option that inserted unexpected
newlines and disabled it as a first thing.
Then I looked around for a cozy background that mcedit and nc both
had. colorscheme darkblue did the trick.
I grew so fond of mcedit style of highlighting <TAB> and trailing
white space that I felt I absolutely needed an equivalent. Otherwise, I
would corrupt Makefiles all the time by expanding <TAB>s to spaces.
Or the other way around. Who knows!
White space highlighting was easy to do with listchars:
set list
set listchars=tab:<->,trail:.Another important feature of mcedit was to preserve original
indentation for newly written lines. That I managed to get close enough
with the below:
" just maintain the indent
set autoindent
" copy the indentation style from previous line
set copyindent
" do preserve tab/space mix on change
set preserveindentI still don’t quite understand what autoindent does, but I get
something mostly reasonable.
Last minor thing that kept confusing me was indistinguishable command prompt area. It was hard to tell if it’s a command or the rest of edited document. Thus, I added a few explicit visual delimiters with:
" always render tabs even if a single file is open
set showtabline=2
" always render status line below
set laststatus=2To avoid inserting garbage when I use Ctrl-<arrows> out of old Emacs
/ mcedit habit I added a hack to recognize these keys in tmux:
" vim enables xterm-style Ctrl-<arrows> keys based on $TERM variable
" name. term=screen-256color does not trigger it. Let's work it around
" by clobbering it.
set term=xterm-256colorAnd that was it! I got good enough vim config as an mcedit
replacement. To clarity: they are absolutely not a drop-in replacement
at this point. They are now both comfortable enough for me to use.
I went through the vimtutor again, wrote a reasonably sized
nix-olde program and got a
pleasant experience.
Along the way I found a few more advanced substitutes for mcedit
features:
- vertical block selectors are done via
Ctrl-v - adding/removing indent for selected lines are done via
Shift-,/Shift-.. - regex lookups and regex substitutes are occasionally helpful. They also work on visual selections and not just full files!
There are still things that I can’t get used to so easily: I’m used to
INSERT mode that is always on in mcedit and emacs. I still keep
getting lost in which mode I am now and find myself to switch there and
back all the time. I’m not sure it’s how it’s supposed to work or I’m
doing vim wrong.
Parting words
So far I’m using vim for a month and slowly discovering small bits
like netrw and tag completion. My
~/.vimrc still fits
on one screen (if comments are removed).
I switched claws-mail from it’s built-in gtk editor to external
alacritty -e vim %s -c 'set filetype=mail' -c 'setlocal spell!'
command. Now I’m actually enjoying writing emails. It’s not a pain
anymore to paste large chunks of code with proper indentation or getting
through the spelling mistakes.
I also added vimium extension in
Firefox to get nicer URL selection and input text navigation.
Maybe vim will stick this time.
Have fun!